Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Picture a vast orchestra performing a grand symphony. Each musician reads from the same sheet but plays a different part, creating harmony through coordination. Modern model serving architectures work in a similar way. Instead of violins and percussion, they use nodes, GPUs, and distributed inference pipelines to generate answers, predictions, and creative outputs for millions of users at once. This orchestral view offers a crisp understanding of why scale matters and why the backstage mechanics of inference are as important as the models themselves. Many engineers first learn this perspective through structured programs such as a gen AI course, where distributed thinking becomes second nature.
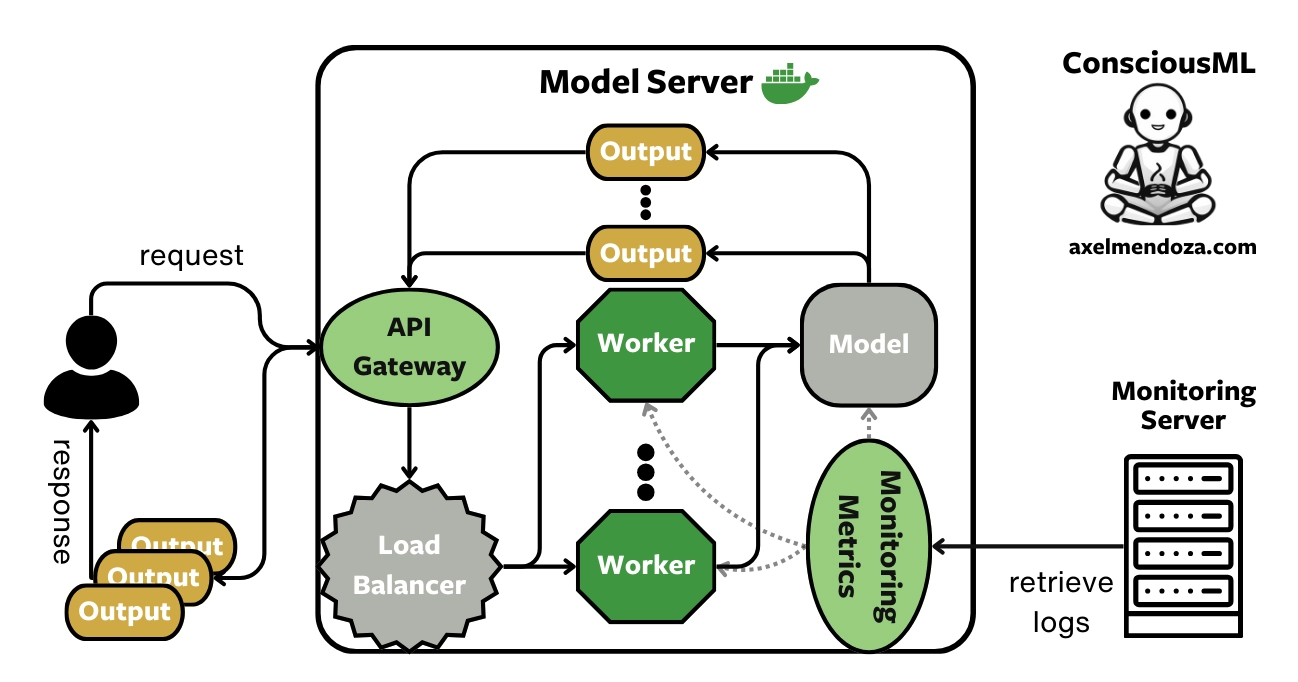
Imagine a single spotlight trying to illuminate an entire stadium. No matter how powerful it is, its reach will fade. A lone model server faces the same limitation when user requests surge. Distributed inference solves this by breaking the generation workload into coordinated tasks across multiple machines that share the load.
In a real world production setting, distributed inference ensures that model responses are fast, consistent, and resilient. When a user in Bengaluru sends a prompt at the same moment another user in Toronto does, the system must react in near real time, not in a slow relay race. By dividing requests among clusters of inference servers, the architecture behaves like a platoon of sprinters instead of a single runner. The focus is on speed, balance, and eliminating bottlenecks through horizontal scaling.
Load balancers are the unsung heroes that keep the environment running with rhythm and grace. They sit at the entry gate, understanding which server is free, which one is warming up, and which one needs a moment of rest. Much like a conductor assigning cues to different sections of the orchestra, a load balancer ensures that no server is overwhelmed.
There are several patterns at play:
In high throughput model serving, even a slight delay in routing can compound into hundreds of slowed interactions. Load balancers therefore maintain heartbeats, perform health checks, and constantly assess which route offers the shortest path to a timely inference. They also act as the first line of defence, preventing cascade failures where one machine going offline could otherwise have brought down an entire cluster.
Large scale generation is rarely a single step process. It is more like flowing water moving through a series of channels and turbines. Distributed inference pipelines divide model computations into sequential or parallel tasks. For example, token generation might run on one device while attention recalculations run on another. Embeddings could be handled on a separate GPU bank, with results merged downstream.
Two important pipeline strategies dominate production systems:
This choreography ensures that no single machine becomes a performance choke point. It also creates redundancy. If a node becomes slow or unresponsive, another one can take over the segment, ensuring uninterrupted flow.
Traffic patterns for model serving often behave like weather systems. Some moments experience a gentle drizzle of queries while others face storms of millions of prompts within minutes. Autoscaling allows the architecture to expand or contract like a breathing organism.
Kubernetes, serverless functions, and cloud orchestration tools make this elasticity possible. As the load increases, the system spins up new inference pods and allocates GPU resources dynamically. When demand drops, it scales back to conserve cost. This elasticity is critical when powering global platforms where peak periods can emerge from time zone shifts, event based surges, or sudden viral attention.
In advanced industrial implementations, engineers integrate prediction algorithms to forecast traffic spikes ahead of time. This proactive approach avoids friction for end users and aligns with modern distributed design principles taught in structured training programs such as a gen AI course, where model lifecycle management is a core module.
Even the best designed systems face outages or anomalies. Distributed inference demands robust fault tolerance so that any single failure remains invisible to users. Redundant GPU clusters, multi regional deployments, active passive failover, and checkpointing strategies keep the machinery humming even when unexpected turbulence arises.
Observability further strengthens reliability. Metrics such as latency, GPU utilisation, request queue lengths, and model refresh times give operations teams deep insight into how the system behaves. Tools like Prometheus, Grafana, ELK stacks, and cloud tracing frameworks ensure complete visibility. Engineers can examine how each inference hop performs, making bottlenecks easier to diagnose before they evolve into production issues.
Designing scalable model serving architectures goes far beyond deploying a model. It demands orchestration, resilience, and a deep appreciation for distributed thinking. From intelligent load balancing to parallelism, autoscaling, and observability, each component contributes to a seamless generation experience. When done well, the system behaves like a symphony that continues playing regardless of how many listeners join. In an era where millions of simultaneous generation requests have become the norm, mastering these patterns is essential for building reliable AI powered platforms that operate at global scale.

